Note: <혼자 공부하는 머신러닝+딥러닝>을 참고 했습니다.
합성곱
여기에서 매우 잘 설명합니다.
주요 용어
- 합성곱(CNN, Convolutional Neural Network)
- 뉴런(Neural) = 필터(filter) = 커널(kernel): 합성곱 신경에서는 완전 연결 신경망과 달리 뉴런을 필터 라고 부릅니다. 혹은 커널이라고도 부릅니다.
- 특정 맵(feature map): 합성곱 계산을 통해 얻은 출력을 특별히 특성맵 이라고 부릅니다.
- 패딩(padding): 입력 배열의 주위를 가상의 원소로 채우는 것
- 세임 패딩(same padding): 입력과 특성 맵의 크기를 동일하게 만들기 위해 입력 주위에 0으로 패딩 하는 것
- 밸리드 패딩(valid padding): 패딩 없이 순수한 입력 배열에서만 합성곱을 하여 특성 맵을 만드는 경우
- 스트라이드(stride)
- 풀링(pooling) 합성곱 층에서 만든 특성 맵의 가로세로 크기를 줄이는 역할을 수행합니다. 하지만 특성맵의 개수는 줄이지 않습니다.(풀링에는 가중치가 없습니다. 대신 최댓값이나 평균값을 계산하는 역할을 수행합니다.
- 최대 풀링(max pooling)
- 평균 풀링(average pooling)
- 풀링을 사용하는 이유: 합성곱에서 스트라이드를 크게 하여 특성 맵을 줄이는 것보다 풀링 층에서 크기를 줄이는 것이 경험적으로 더 나은 성능을 내기 때문입니다.
케라스의 합성곱 층
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
model = keras.Sequential()
model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu',
padding='same', input_shape=(28,28,1)))
model.add(keras.layers.MaxPooling2D(2))
model.add(keras.layers.Conv2D(64, kernel_size=(3,3), activation='relu',
padding='same'))
model.add(keras.layers.MaxPooling2D(2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
---
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 32) 320
max_pooling2d (MaxPooling2 (None, 14, 14, 32) 0
D)
conv2d_1 (Conv2D) (None, 14, 14, 64) 18496
max_pooling2d_1 (MaxPoolin (None, 7, 7, 64) 0
g2D)
flatten (Flatten) (None, 3136) 0
dense (Dense) (None, 100) 313700
dropout (Dropout) (None, 100) 0
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 333526 (1.27 MB)
Trainable params: 333526 (1.27 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
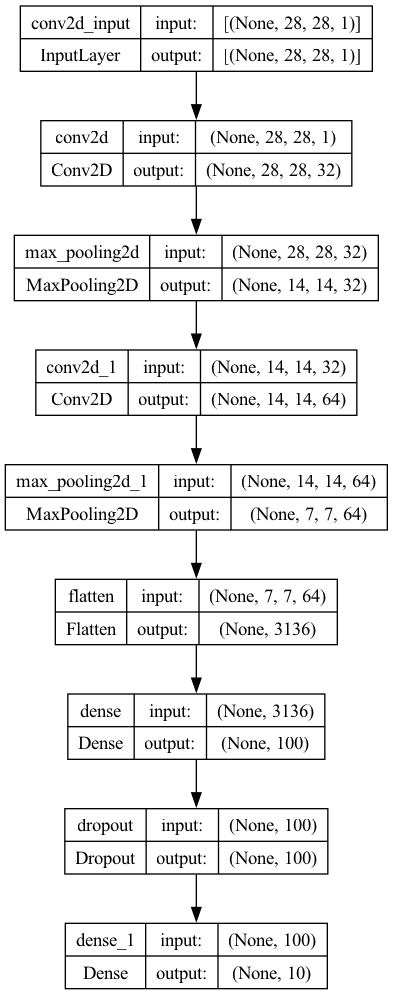
층 시각화
keras.utils.plot_model(model, show_shapes=True)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-cnn-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,
restore_best_weights=True)
history = model.fit(train_scaled, train_target, epochs=20,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
---
1500/1500 [==============================] - 10s 7ms/step - loss: 0.3424 - accuracy: 0.8778 - val_loss: 0.2727 - val_accuracy: 0.8983
...
Epoch 11/20
1500/1500 [==============================] - 10s 7ms/step - loss: 0.1464 - accuracy: 0.9442 - val_loss: 0.2234 - val_accuracy: 0.9258
평가
model.evaluate(val_scaled, val_target)
---
[0.21560314297676086, 0.924833357334137]
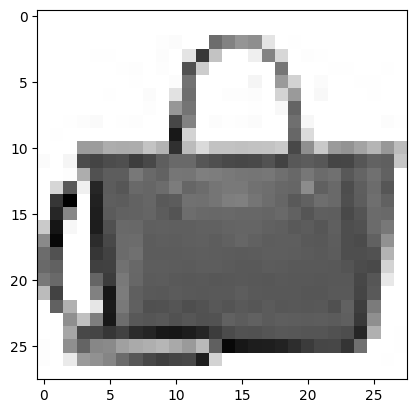
예측 확인
plt.imshow(val_scaled[0].reshape(28, 28), cmap='gray_r')
plt.show()
preds = model.predict(val_scaled[0:1])
print(preds)
---
[[1.2548055e-18 5.6353261e-27 1.8088067e-21 5.3306929e-22 6.4304879e-21 4.2646033e-20 2.4410408e-17 3.6936992e-24 1.0000000e+00 1.1398159e-23]]
출력 결과를 보면 아홉 번째 값이 1이고 다른 값은 거의 0에 가깝습니다. 이전 레이블을 확인해보면
| Label | Description |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
9 번째 가방 으로 잘 예측 한 것 같습니다.