Note: <혼자 공부하는 머신러닝+딥러닝>을 참고 했습니다.
순차 데이터
순차 데이터(sequential data)는 텍스트나 시계열 데이터(time series data) 와 같이 순서에 의미가 있는 데이터를 말합니다.
예를 들어 일별 온도를 기록한 데이터에서 날짜 순서를 뒤죽박죽 섞는다면 내일의 온도를 쉽게 예상하기 어렵습니다.
Note: 예로 패션 MNIST 데이터는 샘플의 순서는 전혀 상관이 없었습니다. 심지어 골고루 섞는 편이 결과가 더 좋습니다.
완전 연결 신경망이나 합성곱 신경망은 이런 기억장치가 없습니다.
하나의 샘플(또는 하나의 배치)을 사용하여 정방향 계산을 수행하고 나면 그 샘플은 버려지고 다음 샘플을 처리할 때 재사용하지 않습니다.
이렇게 입력 데이터의 흐름이 앞으로만 전달되는 신경망을 피드포워드 신경망(feedforward neural network, FFNN)이라고 합니다.
순환 신경망(recurrent neural network, RNN)
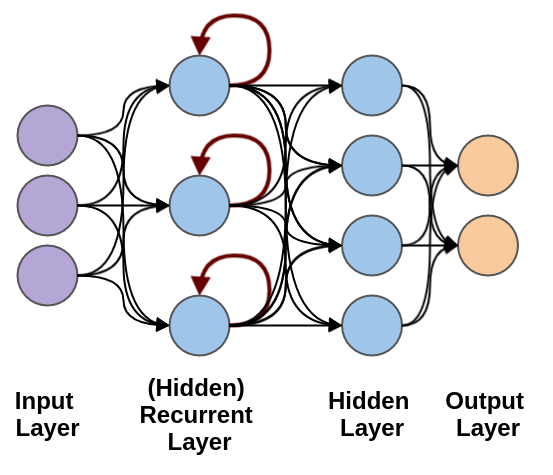
순환 신경망은 일반적인 완전 연결 신경망과 거의 비슷합니다. 완전 연결 신경망에 이전 데이터의 처리 흐름을 순환하는 고리 하나만 추가하면 됩니다. 그림에서 은닉층에 있는 붉은 고리를 눈여겨보세요! 뉴런의 출력이 다시 자기 자신으로 전달 됩니다.
이렇게 샘플을 처리하는 한 단계를 타임스텝(timestep) 이라고 말합니다. 순환 신경망은 이전 타임스텝의 샘플을 기억하지만 타임스텝이 오래 될수록 순환된느 정보는 희미해집니다.
순환 신경망에서는 특별히 층을 셀(cell) 이라고 불브니다. 한 셀에는 여러 개의 뉴런이 있지만 완전 연결 신경망과 달리 뉴런을 모두 표시하지 않고 하나의 셀로 층을 표현합니다. 또 셀의 출력을 은닉 상태(hidden state) 라고 부릅니다.
일반적으로 은닉층의 활성화 함수로는 하이퍼볼렉 탄젠트(hyperbolic tangent)함수인 tanh가 많이 사용 됩니다.
셀의 가중치와 입출력
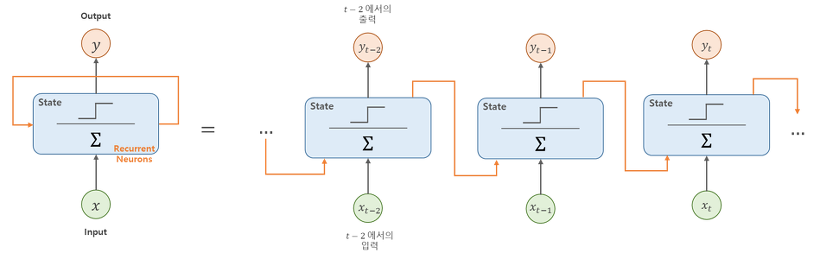
여기를 참고 합니다.
Note: 순환층은 기본적으로 마지막 타임스텝의 은닉 상태만 출력으로 내보냅니다.
순환 신경망으로 IMDB 리뷰 분류하기
텐서플로를 사용해 순환 신경망을 만들어 영화 리뷰 데이터셋에 적용해서 리뷰를 긍정과 부정으로 분류합니다
pad_sequences() 함수는 기본으로 maxlen보다 긴 시퀀스의 앞부분을 자릅니다.
이렇게 하는 이유는 일반적으로 시퀀스의 뒷부분의 정보가 더 유용하리라 기대하기 때문입니다.
만약 시퀀스의 뒷부분을 잘라내고 싶다면 pad_sequences() 함수의 truncating 매개변수의 값을 기본값 ‘pre’가 아닌 ‘post’로 바꾸면 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
from tensorflow.keras.datasets import imdb
(train_input, train_target), (test_input, test_target) = imdb.load_data(
num_words=300)
from sklearn.model_selection import train_test_split
train_input, val_input, train_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42)
from tensorflow.keras.preprocessing.sequence import pad_sequences
val_seq = pad_sequences(val_input, maxlen=100)
케라스는 여러 종류의 순환층 클래스를 제공합니다. 그 중 가장 간단한 것은 SimpleRNN 클래스 입니다.
1
2
3
4
5
6
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.SimpleRNN(8, input_shape=(100, 300)))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.add(keras.layers.SimpleRNN(8, input_shape=(100, 300))) input_shape=(100, 300)으로 지정했습니다. 100은 샘플의 길이를 100으로 지정했기 때문이고 300은 train_oh = keras.utils.to_categorical(train_seq) 로 정수 하나마다 300차원의 배열로 변경되었기 때문입니다.
train_oh = keras.utils.to_categorical(train_seq)
val_oh = keras.utils.to_categorical(val_seq)
Note: keras.utils.to_categorical(train_seq) 는 one-hot Encoding 입니다.

순환신경망 훈련하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
train_oh = keras.utils.to_categorical(train_seq)
val_oh = keras.utils.to_categorical(val_seq)
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-simplernn-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model.fit(train_oh, train_target, epochs=100, batch_size=64,
validation_data=(val_oh, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
1
2
3
4
5
6
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
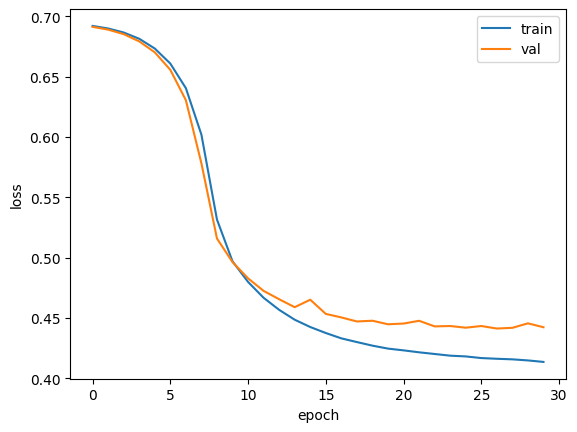
훈련 손실은 꾸준히 감소하고 있지만 검증 손실은 대략 스무 번째 에포크에서 감소가 둔해지고 있습니다.
이 작업을 하기 위해서 입력 데이터를 원-핫 인코딩으로 변환 했습니다. 원-핫 인코딩의 단점은 입력 데이터가 엄청 커진다는 것입니다. 토큰 1개를 300차원으로 늘렸기 때문에 대략 300배가 커집니다. 이를 개선해봅니다.
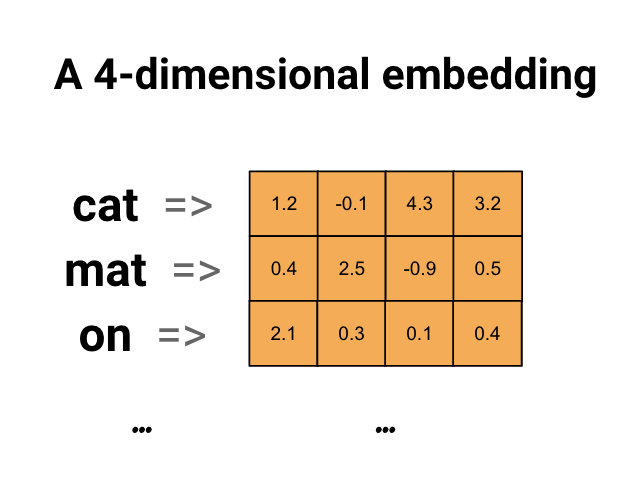
단어 임베딩을 사용하기
순환 신경망에서 텍스트를 처리할 때 즐겨 사용하는 방법은 단어 임베딩(word embedding) 입니다. 단어 임베딩은 각 단어를 고정된 크기의 실수 벡터로 바꾸어 줍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(300, 16, input_length=100))
model2.add(keras.layers.SimpleRNN(8))
model2.add(keras.layers.Dense(1, activation='sigmoid'))
model2.summary()
---
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 16) 4800
simple_rnn_1 (SimpleRNN) (None, 8) 200
dense_1 (Dense) (None, 1) 9
=================================================================
Total params: 5009 (19.57 KB)
Trainable params: 5009 (19.57 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
1
2
3
4
5
6
7
8
9
10
11
12
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model2.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-embedding-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model2.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
LSTM(Long Short-Term Memory)
LSTM은 여기의 설명을 참고합니다.
LSTM은 단기 기억을 오래 기억하기 위해 고안되었습니다. LSTM에는 순환되는 상태가 2개입니다. 은닉 상태 말고 셀 상태(cell state)라고 부른느 값이 또 있죠. 은닉 상태와 달리 셀 상태는 다음 층으로 전달되지 않고 LSTM 셀에서 순환만 되는 값입니다.
LSTM 신경망 훈련하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(500, 16, input_length=100))
model2.add(keras.layers.LSTM(8, dropout=0.3))
model2.add(keras.layers.Dense(1, activation='sigmoid'))
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model2.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-dropout-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model2.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
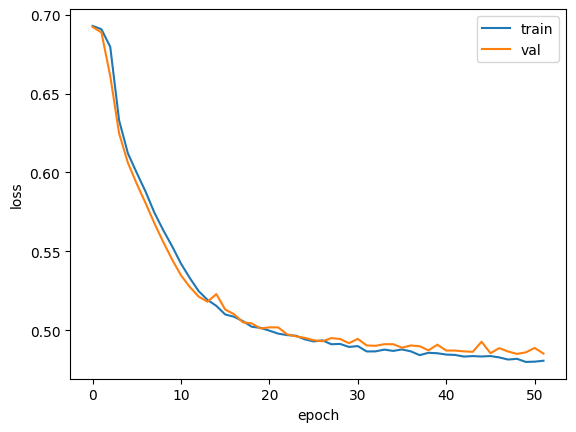
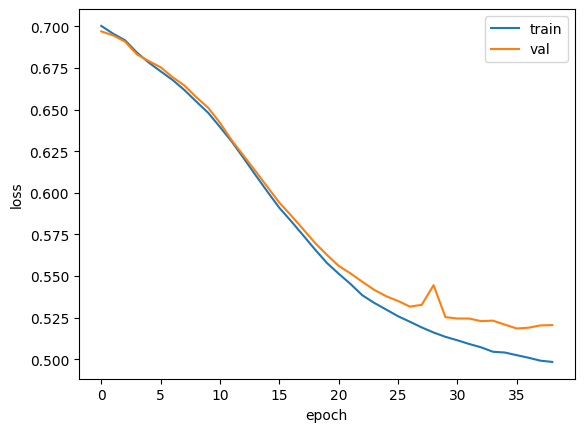
그래프를 보면 기본 순환층보다 LSTM이 과대적합을 억제하면서 훈련을 잘 수행한 것으로 보입니다.
Note: 경우에 따라서 과대적합을 더 강하게 제어할 필요도 있습니다. 또한 Drop 을 적용하거나 여러개의 순환층을 연결하여 성능 튜닝도 가능합니다.
GRU(Gated Recurrent Unit)
여기의 설명을 참고 합니다.
GRU는 Gated Recurrent Unit의 약자입니다.
이 셀은 LSTM을 간소화한 버전으로 생각할 수 있습니다. 이 셀은 LSTM처럼 셀 상태를 계산하지 않고 은닉 상태 하나만 포함하고 있습니다.
GRU 셀에는 은닉 상태와 입력에 가중치를 곱하고 절편을 더하는 작은 셀이 3개 들어 있습니다. 2개는 시그모이드 활성화 함수를 사용하고 하나는 tanh 활성화 함수를 사용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
model4 = keras.Sequential()
model4.add(keras.layers.Embedding(500, 16, input_length=100))
model4.add(keras.layers.GRU(8))
model4.add(keras.layers.Dense(1, activation='sigmoid'))
model4.summary()
---
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 100, 16) 8000
gru (GRU) (None, 8) 624
dense_3 (Dense) (None, 1) 9
=================================================================
Total params: 8633 (33.72 KB)
Trainable params: 8633 (33.72 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
msprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model4.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-gru-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model4.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()