Note: <혼자 공부하는 머신러닝+딥러닝>을 참고 했습니다.
인공신경망(ANN, artificial neural network)
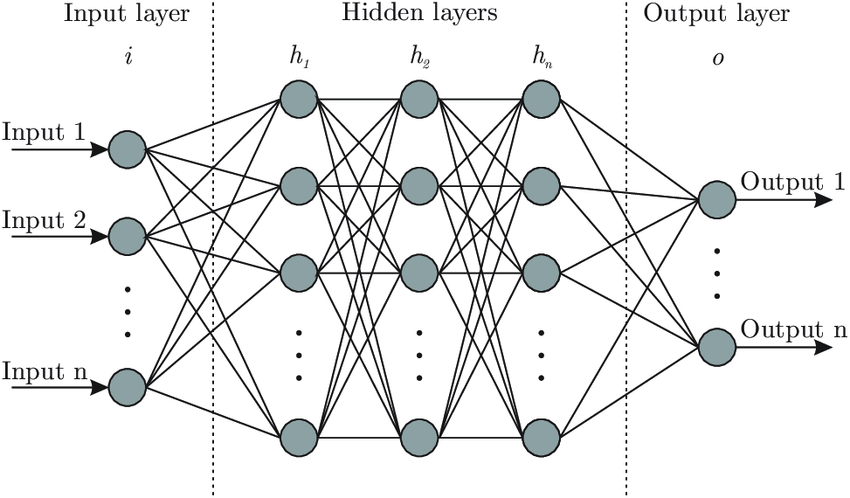
가장 기본적인 인공 신경망은 확률적 경사 하강법을 사용하는 로지스틱 회귀와 같습니다.
인공신경망에서 출력값(output) 값을 계산하는 단위를 뉴런(neuron)이라고 합니다.
뉴런에서 일어나는 일은 선형 계산이 전부 입니다. 이제는 뉴런이란 표현 대신 유닛(unit) 이라고 부르는 사람이 더 많아지고 있습니다.
Input 1은 가중치 값 입니다. 절편은 뉴런마다 하나씩이므로 순서대로 각 뉴런의 선형계산에 더해줍니다.
Note: 딥러닝은 인공신경망과 거의 동의어로 사용되는 경우가 만흣ㅂ니다. 혹은 심층 신경망(deep neural network, DNN)을 딥러닝이라고 부릅니다.
데이터 준비
Note: Data Source: https://github.com/zalandoresearch/fashion-mnist/tree/master
1
2
3
4
5
6
7
8
9
10
11
12
import tensorflow as tf
tf.keras.utils.set_random_seed(42)
tf.config.experimental.enable_op_determinism()
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)
---
(60000, 28, 28) (60000,)
패션 MNIST에 포함된 10개의 레이블의 의미는 아래와 같습니다.
| Label | Description |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
print(np.unique(train_target, return_counts=True))
---
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000]))
인공 신경망으로 모델 만들기
Note: 여러가지 머신러닝 라이브러리중 keras를 사용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
from sklearn.model_selection import train_test_split
from tensorflow import keras
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))
model = keras.Sequential(dense)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
model.evaluate(val_scaled, val_target)
---
[0.45983508229255676, 0.8460000157356262]
케라스의 레이어(keras.layers) 패키지 안에는 다양한 층이 준비되어 있습니다.
가장 기본이 되는 층은 밀집층(dense layer) 입니다.
이런 층을 양쪽의 뉴런이 모두 연결하고 있기 때문에 완전 연결층(fully connected layer)이라고도 부릅니다.
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy') 이진분류에서는 이진 크로스 엔트로피 손실 함수를 사용합니다. 다중 분류에서는 크로스 엔트로피 손실 함수를 사용 합니다.
- 이진분류: loss=’binary_crossentropy
- 다중분류: logg =’categorical_crossentropy
심층 신경망
Note: 출력층에 적용하는 활성화 함수는 종류가 제한 되어 있지만 은닉층의 활성화 함수는 비교적 자유롭습니다.
앞에서 만든 신경망 모델과 다른 점은 입력층과 출력층 사이에 밀집층이 추가된 것입니다.
이렇게 입력층과 출력층 사이에 있는 모든 층을 은닉층(hidden layer)이라고 부릅니다.
은닉층의 활성화 함수는 출력층에 비해 자유롭습니다. 대표적으로 시그모이드 함수와 볼 렐루(ReLu) 함수 등을 사용 합니다.
심층 신경망을 만들때 한 가지 제약 사항이 있다면 적어도 출력층의 뉴런보다는 많게 만들어야 합니다. 클래스 10개에 대한 확률을 예측해야 하는데 이전 은닉층의 뉴런이 10개보다 적다면 부족한 정보가 전달될 것 입니다.
1
2
3
4
5
6
7
8
9
10
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10, activation='softmax')
model = keras.Sequential([dense1, dense2])
model.summary()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
model.evaluate(train_scaled, train_target)
---
[0.32170307636260986, 0.8847083449363708]
렐루 함수(ReLU)
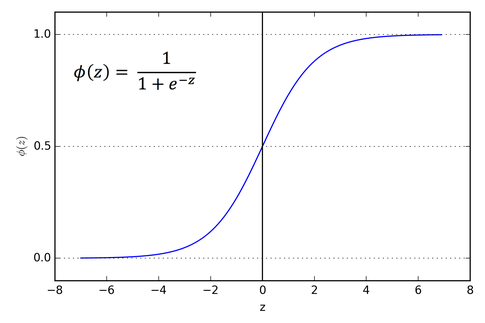
초창기 인공 신경망의 은닉층에 많이 사용된 활성화 함수는 시그모이드 함수였습니다.
하지만 이 함수에는 단점이 있습니다. 이 함수의 오른쪽과 끝으로 갈수록 그래프가 누워있기 때문에 올바른 출력을 만드는데 신속하게 대응하지 못합니다.
특히 층이 많은 심층 신경망일수록 그 효과가 누적되어 학습을 더 어렵게 만듭니다. 이를 개선하기 위해 다른 종류의 활성화 함수가 제안되었습니다.
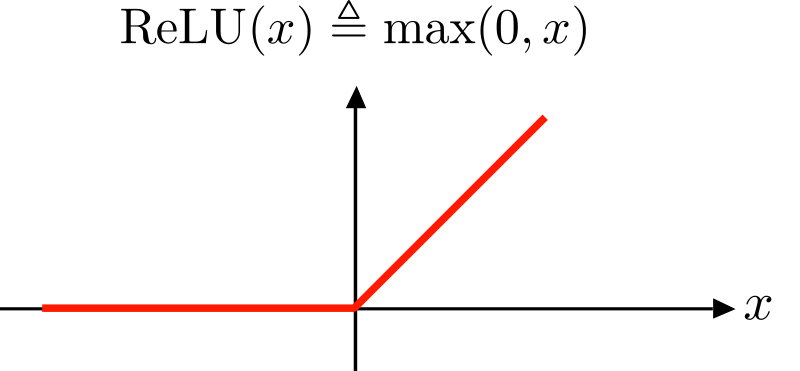
렐루(ReLU)함수 입니다. 렐루 함수는 아주 간단합니다.
입력이 양수일 경우 마치 활성화 함수가 없는 것처럼 그냥 입력을 통과시키고 음수일 경우에는 0으로 만듭니다.
1
2
3
4
5
6
7
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
Flatten 클래스는 배치 차원을 제외하고 나머지 입력 차원을 모두 일렬로 펼치는 역할만 합니다. 입력에 곱해진느 가중치나 절편이 없죠. 따라서 인공 신경망의 성능을 위해 기여하는 바는 없습니다. Flatten클래스를 층처럼 입력층과 은닉층 사이에 추가하기 때문에 이를 층이라 부릅니다. Flatten 층은 다음 코드처럼 입력층 바로 뒤에 추가합니다.
옵티마이저
신경망에는 특히 하이퍼파라미터가 많습니다. 케라스는 기본적으로 미니배치 경사 하강법을 사용하며 미니배치 개수는 32개 입니다. fit() 메서드의 batch_size 매개변수에서 이를 조정할 수 있으며 역시 하이퍼파라미터입니다.
케라스에는 다양한 종류의 경사 하강법 알고리즘을 제공합니다. 이들을 옵티마이저(optimizer)라고 부릅니다.
1
2
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')
기본 경사 하강법 옵티마이저는 모두 SGD 클래스에서 제공합니다. SGD 클래스의 momentum 매개변수의 기본값은 0입니다. 이를 0보다 큰 값으로 지정하면 마치 이전의 그레이디언트를 가속도처럼 사용하는 모멘텀 최적화(momentum optimization)을 사용합니다.
SGD 클래스의 nesterov 매개변수를 기본값 False 에서 True로 바꾸면 네스테로프 모멘텀 최적화(nesterov momentum optimization)를 사용합니다.
네스테로프 모멘텀은 모멘텀 최적화를 2번 반복하여 구현합니다. 대부분의 경우 네스테로프 모멘텀 최적화가 기본 확률적 경사 하강법 보다 더 나은 성능을 제공합니다.
또한 모델이 최적점에 가까이 갈수록 확습률을 낮출 수 있습니다 이렇게 하면 안정적으로 최적점에 수렴할 가능성이 높습니다. 이런 학습률을 적응적 학습률(adaptive learning rate)이라고 합니다. 이런 방식들은 학습률 매개변수를 튜닝하는 수고를 덜 수 있는 것이 장점입니다.
adagrad = keras.optimizers.Adagrad()
model.compile(optimizer=adagrad, loss='sparse_categorical_crossentropy', metrics='accuracy')
---
rmsprop = keras.optimizers.RMSprop()
model.compile(optimizer=rmsprop, loss='sparse_categorical_crossentropy', metrics='accuracy')
모멘텀 최적화와 RMSprop의 장점을 접목한 것이 Adam 입니다. Adam 은 RMSprop과 함께 맨처음 시도해볼 수 있는 좋은 알고리즘 입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
model.evaluate(val_scaled, val_target)