Note: <혼자 공부하는 머신러닝+딥러닝>을 참고 했습니다.
앞 포스팅혼자공부하는 머신러닝 정리 4 (k-최근접 이웃 회귀)에서 k-최근접 이웃 회귀 알고리즘을 다뤘습니다.
k-최근접 이웃 회귀 알고리즘은 학습한 모델의 데이터와 비교했을때, 학습하지 않은 특정값에 대해 예측을 잘 못하는 한계가 있습니다. 이를 확인해보죠.
데이터 준비
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
## k-최근접 이웃의 한계
import numpy as np
perch_length = np.array(
[8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
)
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)
from sklearn.model_selection import train_test_split
# 훈련 세트와 테스트 세트로 나눕니다
train_input, test_input, train_target, test_target = train_test_split(
perch_length, perch_weight, random_state=42)
# 훈련 세트와 테스트 세트를 2차원 배열로 바꿉니다
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
그 후 KNeighborsRegressor 모델을 훈련합니다.
1
2
3
4
5
6
7
8
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor(n_neighbors=3)
# k-최근접 이웃 회귀 모델을 훈련합니다
knr.fit(train_input, train_target)
print(knr.predict([[50]]))
> [1033.33333333]
50cm 짜리 농어 무게를 1.033g 으로 예측 했습니다. 하지만 실제 이 농어의 무게는 훨씬 더 많이 나갑니다. 문제가 무엇일까요?
시각화
1
2
3
4
5
6
7
8
9
10
11
12
13
import matplotlib.pyplot as plt
# 50cm 농어의 이웃을 구합니다
distances, indexes = knr.kneighbors([[50]])
# 훈련 세트의 산점도를 그립니다
plt.scatter(train_input, train_target)
# 훈련 세트 중에서 이웃 샘플만 다시 그립니다
plt.scatter(train_input[indexes], train_target[indexes], marker='D')
# 50cm 농어 데이터
plt.scatter(50, 1033, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
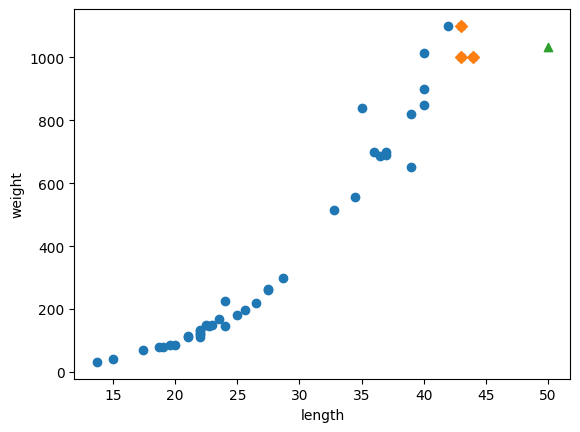
k-최근접 이웃 알고리즘은 이 샘플들의 무게를 평균합니다. 따라서 길이가 커질수록 무게가 커지지만… 훈련한 모델의값을 기준으로 하기 때문에 특정 범위를 벗어나도 예측값이 변하지 않습니다.
1
2
3
4
5
6
7
8
9
10
11
12
# 100cm 농어의 이웃을 구합니다
distances, indexes = knr.kneighbors([[100]])
# 훈련 세트의 산점도를 그립니다
plt.scatter(train_input, train_target)
# 훈련 세트 중에서 이웃 샘플만 다시 그립니다
plt.scatter(train_input[indexes], train_target[indexes], marker='D')
# 100cm 농어 데이터
plt.scatter(100, 1033, marker='^') # knr.kneighbors([[100]]) 의 결과값만 넣습니다.
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
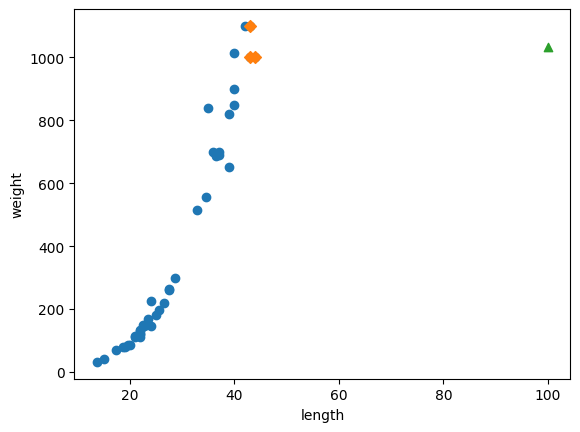
Note: 머신러닝 모델은 주기적으로 훈련해야 합니다. 시간과 환겨이 변화하면서 데이터도 바뀌기 때문에 주기적으로 새로운 훈련 데이터로 모델을 다시 훈련해야 합니다.
선형 회귀(linear regression)
선현 회귀는 널리 사용되는 대표적인 회귀 알고리즘입니다. 비교적 간단하고 성능이 뛰어나기 때문에 맨 처음 배우는 머신러닝 알고리즘 중 하나 입니다. 선형이란 말에서 짐작할 수 있듯이 특성이 하나인 경우 어떤 직선을 학습하는 알고리즘입니다.

1
2
3
4
5
6
7
8
9
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# 선형 회귀 모델 훈련
lr.fit(train_input, train_target)
# 50cm 농어에 대한 예측
print(lr.predict([[50]]))
> [1241.83860323]
print(lr.coef_, lr.intercept_)
> [39.01714496] -709.0186449535474
선형 회귀가 하나의 직선을 그리려면 (1) 기울기 (2) 절편이 있어야 합니다 $y = a * x + b$ 처럼 쓸 수 있죠. LinearRegression 클래스가
1
2
3
4
5
6
7
8
9
# 훈련 세트의 산점도를 그립니다
plt.scatter(train_input, train_target)
# 15에서 50까지 1차 방정식 그래프를 그립니다
plt.plot([15, 50], [15*lr.coef_+lr.intercept_, 50*lr.coef_+lr.intercept_])
# 50cm 농어 데이터
plt.scatter(50, 1241.8, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
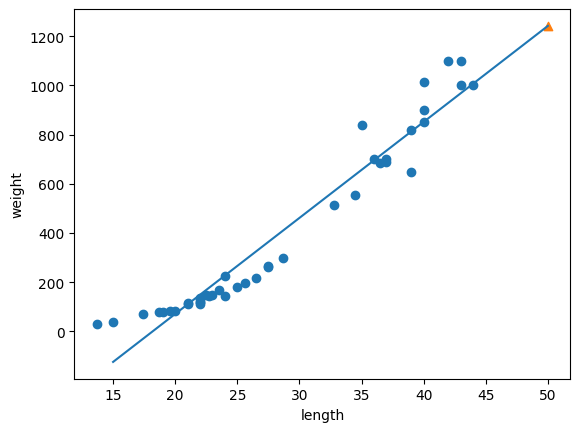
coef_와 _intercept_를 머신러닝 알고리즘이 찾은 값이라는 의미로 모델 파라미터(model parameter)라고 부릅니다. 많은 머신러닝 알고리즘의 훈련 과정은 최적의 모델 파라미터를 찾는 것과 간ㅌ습니다. 이를 모델 기반 학습 이라고 부릅니다. 앞서 k-최근접 이웃에는 모델 파라미터가 없습니다. 훈련 세트를 저장하는 것이 훈련의 전부였죠. 이를 사례 기반 학습이라고 부릅니다.
print(lr.score(train_input, train_target))
print(lr.score(test_input, test_target))
> 0.9398463339976041
> 0.824750312331356
이 모델이 훈련 세트에 과대적합되었다고 말할 수 있을까요? 사실 훈련 세트의 점수도 높지 않습니다. 오히려 전체적으로 과소적합되었다고 볼 수 있죠. 🤔🤔
과소적합 말고도 다른 문제가 또 있습니다. 그래프 왼쪽 아래를 보세요. 무게가 음수 입니다.
다항회귀
기존에 train_input 데이터를 갖고 numpy를 사용하여 쉽게 만들 수 있습니다.
train_poly = np.column_stack((train_input ** 2, train_input))
test_poly = np.column_stack((test_input ** 2, test_input))
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.predict([[50**2, 50]]))
> [1573.98423528]
print(lr.coef_, lr.intercept_)
> [ 1.01433211 -21.55792498] 116.0502107827827
# 구간별 직선을 그리기 위해 15에서 49까지 정수 배열을 만듭니다
point = np.arange(15, 50)
# 훈련 세트의 산점도를 그립니다
plt.scatter(train_input, train_target)
# 15에서 49까지 2차 방정식 그래프를 그립니다
plt.plot(point, 1.01*point**2 - 21.6*point + 116.05)
# 50cm 농어 데이터
plt.scatter([50], [1574], marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
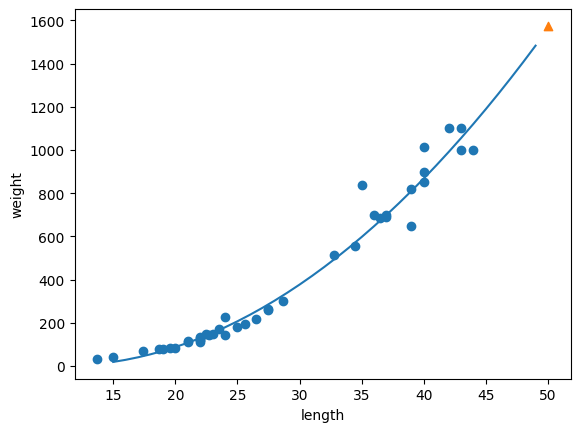
print(lr.score(train_poly, train_target))
print(lr.score(test_poly, test_target))
> 0.9706807451768623
> 0.9775935108325122
훈련 세트와 테스트 세트에 대한 점수가 크게 높아졌습니다. 하지만 여전히 테스트 세트의 점수가 조금 더 높습니다. 과소적합이 아직 남아 있습니다. 좀 더 복잡한 모델이 필요해보입니다.