Note: <혼자 공부하는 머신러닝+딥러닝>을 참고 했습니다.
- 검증 세트가 필요한 이유를 이해하고 교차 검증에 대해 알아봅니다.
- 그리드 서치와 랜덤 서치를 이용해 최적의 성능을 내는 하이퍼파라미터를 찾아봅니다
검증 세트
지금까지 훈련 세트에서 모델을 훈련하고 테스트 세트에서 모델을 평가했습니다. 테스트 세트에서 얻은 점수를 보고 실전 투입에서 어느정도 성능을 낼지 가늠 했었죠.
그런데 테스트 세트를 사용해 자꾸 성능을 확인하다 보면 점점 테스트 세트에 맞추게 되는셈 입니다.
테스트 세트를 사용하지 않으면 모델이 과대적합인지 과소적합인지 판단하기 어렵습니다. 테스트 세트를 사용하지 않고 이를 측정하는 간단한 방법은 훈련 세트를 또 나누는 거죠!
이 데이터를 검증 세트(validation set)라고 부릅니다.
Note: 보통 20~30%를 테스트 세트와 검증 세트로 떼어 놓습니다. 하지만 문제에 따라 달브니다. 훈련 데이터가 아주 많다면 몇 %만 떼어 놓아도 전체 데이터를 대표하는 데 문제가 없습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
## 테스트 세트
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42)
## 검증 세트
sub_input, val_input, sub_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42)
print(sub_input.shape, val_input.shape)
...
테스트 세트와 검증세트를 나눴습니다.
훈련 세트의 개수가 줄었습니다. 보통 많은 데이터를 훈련에 사용할수록 좋은 모델이 만들어집니다.
그렇다고 검증 세트를 너무 조금 떼어 놓으면 검증 점수가 들쭉날쭉하고 불안정할 것 입니다.
이럴 때 교차 검증(cross validation) 을 이용하면 안정적인 검증 점수를 얻고 훈련에 더 많은 데이터를 사용할 수 있습니다.
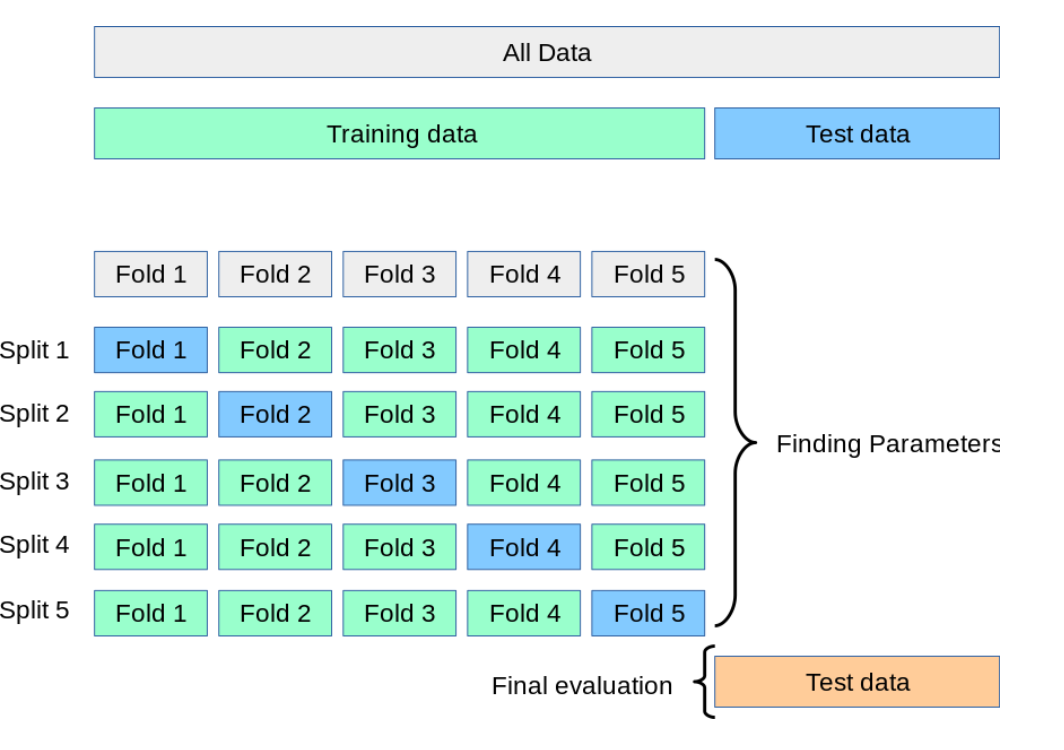
Note: https://scikit-learn.org/stable/modules/cross_validation.html
훈련 세트를 세 부분으로 나눠서 교차 검증을 수행하는 것을 3-폴드 교차 검증이라고 합니다. 통칭 k-폴드 교차 검증 이라고 하며, 훈련 세트를 몇부분으로 나누냐에 따라 다르게 부릅니다.
k-겹 교차 검증이라고도 부릅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
---
> {'fit_time': array([0.00297499, 0.00199604, 0.00181484, 0.00196123, 0.00269604]), 'score_time': array([0.00052404, 0.00028586, 0.00027108, 0.00055766, 0.00047612]), 'test_score': array([0.84230769, 0.83365385, 0.84504331, 0.8373436 , 0.8479307 ])}
---
import numpy as np
print(np.mean(scores['test_score']))
---
0.8412558303102096
이름은 test_score 지만 검증 폴드의 점수 입니다.(혼동하지 마세요)
한가지 주의할 점은 cross_validate()는 훈련 세트를 섞어 폴드를 나누지 않습니다. 앞서 우리는 train_test_split() 함수로 전체 데이터를 섞은 후 훈련 세트를 준비했기 때문에 따로 섞을 필요가 없습니다. 하지만 만약 교차 검증을 할 때 훈련 세트를 섞으려면 분할기(splitter)를 지정해야 합니다.
사이킷런의 분할기는 교차 검증에서 폴드를 어떻게 나눌지 결정해 줍니다.
cross_validate() 함수는 기본적으로 회귀 모델일 경우 KFold 분할기를 사용하고 분류 모델일 경우 타깃 클래스를 골고루 나누기 위해 StratifiedKFold를 사용합니다.
1
2
3
4
5
6
from sklearn.model_selection import StratifiedKFold
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
print(np.mean(scores['test_score']))
---
8412558303102096
만약 훈련 세트를 섞은 후 10-폴드 교차 검증을 수행하려면 다음고 ㅏ같이 작성합니다.
1
2
3
4
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score']))
---
그리드 서치
머린러닝 모델이 학습하는 파라미터를 모델 파라미터라고 부릅니다. 반면에 모델이 학습할 수 없어서 사용자가 지정해야만 하는 파라미터를 하이퍼파라미터라고 합니다.
하이퍼파라미터를 튜닝할땐 검증 세트의 점수나 교차 검증을 통해서 매개변수를 조금씩 바꿔봅니다. 매개변수들을 바꿔가면서 모델을 훈련하고 교차검증 수행하죠.
하지만 이런 매개변수가 여러개라면?
각 매개변수가 서로에게 영향을 미칠땐 어떻게 해야할까요?
하나씩 지정하여 실행할수도 있지만 사이킷런에서 이미 만들어진 도구가 있습니다 그리드 서치(Grid Search) 입니다.
1
2
3
4
5
6
7
8
9
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
dt = gs.best_estimator_
print(dt.score(train_input, train_target))
---
0.9615162593804117
GridSearchCV는 하이퍼파라미터 탐색과 교차 검증을 한 번에 수행 합니다.
GridSearchCV의 cv 매개변수 기본값은 5 입니다.
따라서 min_impurity_decrease 값맏 5-폴드 교차 검증을 수행합니다.
결국 5*5=25 개의 모델을 훈련합니다.
많은 모델을 훈련하기 때문에 GridSearchCV 클래스의 n_jobs 매개변수에서 병렬 실행에 사용할 CPU 코어 수를 지정하는 것이 좋습니다. 이 매개변수는 -1 입니다.
사이킷런의 그리드 서치는 훈련이 끝나면 25개의 모델 중에서 검증 점수가 가장 높은 모델의 매개변수 조합으로 전체 훈련 세트에서 자동으로 다시 모델을 훈련합니다.
이 모델은 gs 객체의 best_estimator_속성에 저장되어 있습니다.
dt = gs.best_estimator_
print(dt.score(train_input, train_target))
랜덤 서치
매개변수의 값이 수치일 때 값의 범위나 간격을 미리 정하기 어려울 수 있습니다. 또 너무 많은 매개 변수 조건이 있어 그리드 서치 수행 시간이 오래 걸릴 수 있습니다.
이럴 때 랜덤 서치(Random Search)를 사용하면 좋습니다.
랜덤 서치에는 매개변수 값의 목록을 전달하는 것이 아니라 매개변수를 샘플링할 수 있는 확률 분포 객체를 전달합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from scipy.stats import uniform, randint
params = {'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25),
}
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params,
n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)
print(gs.best_params_)
print(np.max(gs.cv_results_['mean_test_score']))
---
{'max_depth': 39, 'min_impurity_decrease': 0.00034102546602601173, 'min_samples_leaf': 7, 'min_samples_split': 13}
0.8695428296438884