Note: <혼자 공부하는 머신러닝+딥러닝>을 참고 했습니다.
길이와 무게가 있는 생선데이터를 가지고 k-최근접 알고리즘을 사용하여 모델을 만들고 성능을 평가 해봅니다.
이진분류: 머신러닝에서 여러 개의 종류(혹은 클래스(class)라고 불브니다) 중 하나를 구별해 내는 문제를 분류(classification)라고 부릅니다. 2개의 클래스 중 하나를 고르는 문제를 이진 분류(binary classification)라고 부릅니다.
데이터 준비
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0, 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0, 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0, 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
## 두 종류의 생선 데이터 합치기
length = bream_length+smelt_length
weight = bream_weight+smelt_weight
fish_data = [[l, w] for l, w in zip(length, weight)]
## 정답 만들기
fish_target = [1]*35 + [0]*14
print(fish_target)
print(fish_data)
길이가 30cm, 무게가 600g인 생선은 bream, smelt 중 무엇일까요?
1
2
3
4
5
6
7
8
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.scatter(30, 600, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
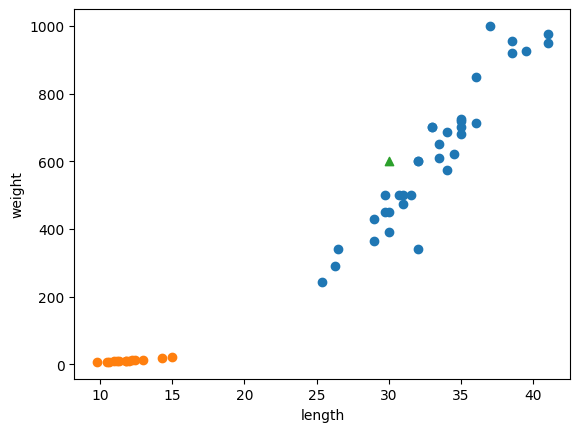
대상(plt.scatter(30, 600, marker='^')) 주위에 bream이 있으니 bream일 확률이 높아보입니다.
KNeighborsClassifier
사이킷런 패키지에 k-최근접 이웃 알고리즘을 구현한 클래스인 KNeighborsClassifier를 임포트 합니다.
1
2
3
4
5
6
7
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target)
kn.score(fish_data, fish_target)
> 1.0
sklearn의 KNeighborsClassifier을 사용합니다. 결과로 1.0을 반환합니다. 이 값을 정확도(accuracy)라고 부릅니다.
머신러닝 알고리즘을 구현한 프로그램을 모델(model)이라고 부릅니다. ex) “스팸 메일을 걸러내기 위해 k-최근접 이웃 모델을 사용해 봅시다” 라고 말할 수 있습니다.
1
2
print(kn.predict([[30, 600]]))
[1]
predict() 메서드는 새로운 데이터의 정답을 예측합니다. bream는 1 smelt는 0 입니다.
k-최근접 이웃 알고리즘은 새로운 데이터에 대해 가장 가까운 직선거리에 어떤 데이터가 있는지 살피기만 하면 됩니다. 단점은 이런 특징 때문에 데이터가 아주 많은 경우 사용하기 어렵습니다. 데이터가 크기 때문에 메모리가 많이 필요하고 직선거리를 계산하는 데도 많은 시간이 필요합니다.
k-최근접 이웃 알고리즘이 참고 데이터 개수의 기본값은 5 입니다. KNeighborsClassifier(n_neighbors=49)를 사용하여 참고데이터 개수를 변경할 수 있습니다.