Q: 컴퓨터는 어떻게 문자를 저장 할까?
컴퓨터의 메모리는 비트를 저장하고 사용합니다. 우리가 알고 있는 세계의 다양한 문자들을 사용 하려면 컴퓨터에게 ‘지정’ 을 해주어야 합니다. 초창기에 다양한 방법으로 문자를 표현 했는데, 호환 등 여러가지 문제가 발생 했습니다. 이런 문제를 해결하기 위해 ANSI1(American National Standards Institute) 에서 ASCII(American Standard Code for Information Interchange)라는 표준 코드 체계를 제시했고, 현재 이 코드가 일반적으로 사용되고 있다. ASCII 는 미국에서 맨처음 개발 되었습니다.
이러한 작업에서 가장 처음으로 가져야 하는 질문은 부호를 만들 때 각각 몇 비트를 사용할 것인가 입니다..!
정답부터 이야기 하면 ASCII 는 7 비트 입니다
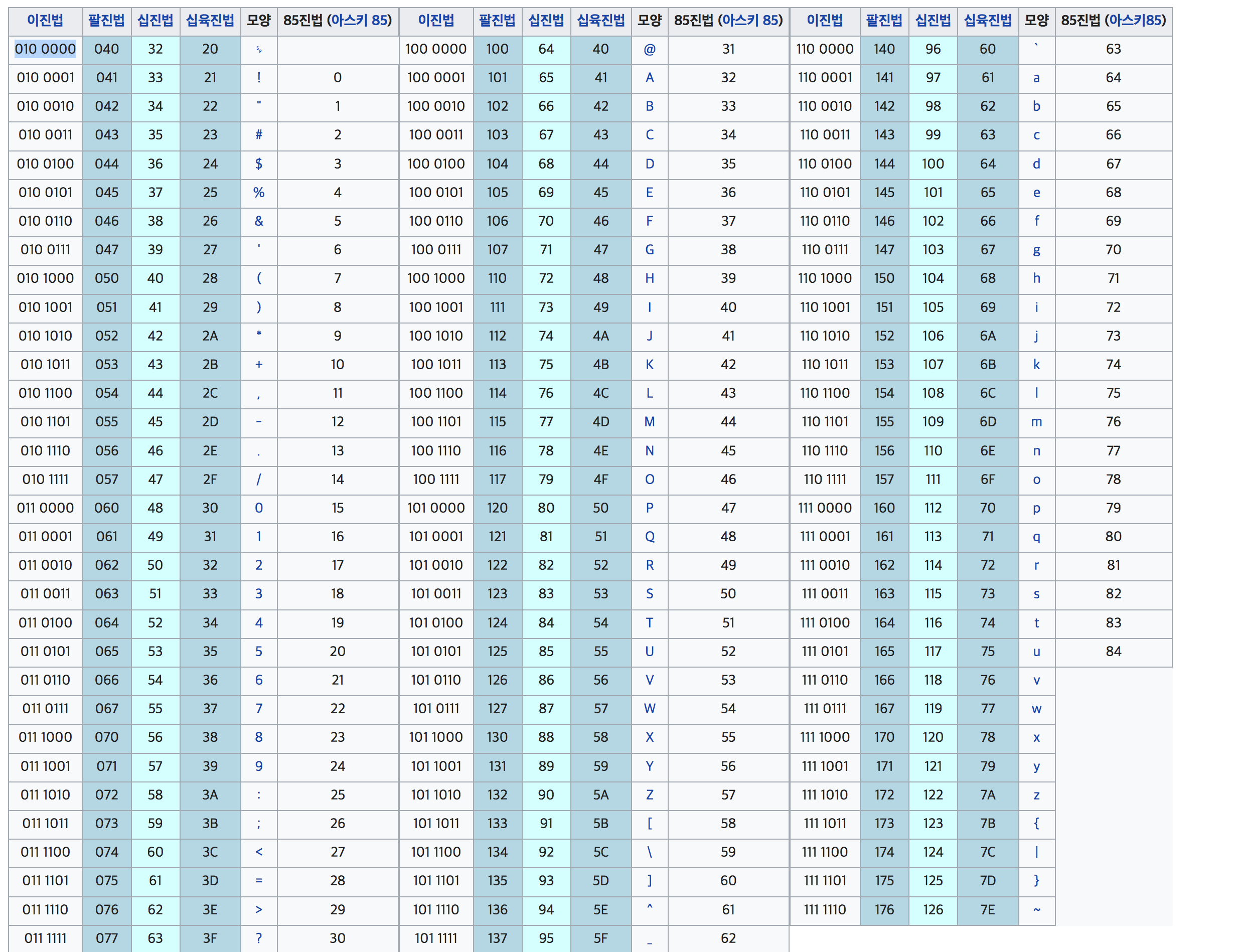
위의 이미지처럼, 7비트에 각각 문자와, 특수문자 등을 대응 시키는 table을 만들어서 표준으로 사용하고 있습니다.
ASCII : 2^7(128 가지 문자 지정 가능) 영단어와, 로마자 및 특수 문자 몇개를 담기에 충분한 가지수
이렇게 표준을 정하니, 문자 문제가 해결이 된것 같았습니다. 그런데, 어느날 일본에서 -> 미국으로 e-mail 이 왔는데, 글자가 깨져 버립니다… 이때 부터 ASCII 만으로 한계가 있다는것을 알게 됩니다.
ASCII 가 기반인 UNICODE
UNICODE : 2 byte (2의 16승 : 65,536가지 문자)
세계의 다양한 문자를 담아서, 전세계 컴퓨터 사용자가 공통으로 사용하는 표준을 만들기 시작합니다. 한글 및 많은 언어가 포함되어 있고, 모든 인코딩 방법을 대체하려고 합니다.
UNICODE 는 ASCII의 확장판입니다. 잘 보면, 아직 모두 채워지지 않았는데, 외계인의 언어도 넣기 위해서 비워 놨다고 합니다….ㅎㅎㅎㅎㅎ